Rock Climbing Route Recommender
Summary
The goal of the project was to build a recommendation system for rock climbing routes. Specifically the task of the recommender systems was to provide either a user’s estimated rating of new route or provide a list of top-K routes for a user based upon their ratings of past climbs.
Data Collection
The data for the project comes from Mountain Project’s API. Mountain Project is a crowd sourced guidebook where users are able to submit information on climbing routes as well as keep a logbook of routes that they have climbed. At the time of data collection there is information on 222,301 outdoor climbing routes of various types such as bouldering, sport, etc. The routes are primarily located in the United States with some international routes being included as well. For each route we have collected the name, type, difficulty rating, star rating, number of star votes, number of pitches, and geographic information. In addition to the route information we have also collected data on users’ logged climbs called ticks. For each tick we have collected the user id, route id, date of the climb, style, lead style, star rating, difficulty rating, and notes on the climb. From the Mountain Project’s data API we were able to gather 4,264,616 logged climbs from 90,545 users on 160,960 distinct routes. Of these logged climbs we have explicit user ratings for 1,980,432 of them on a rating scale of 0 to 4.
Exploratory Analysis
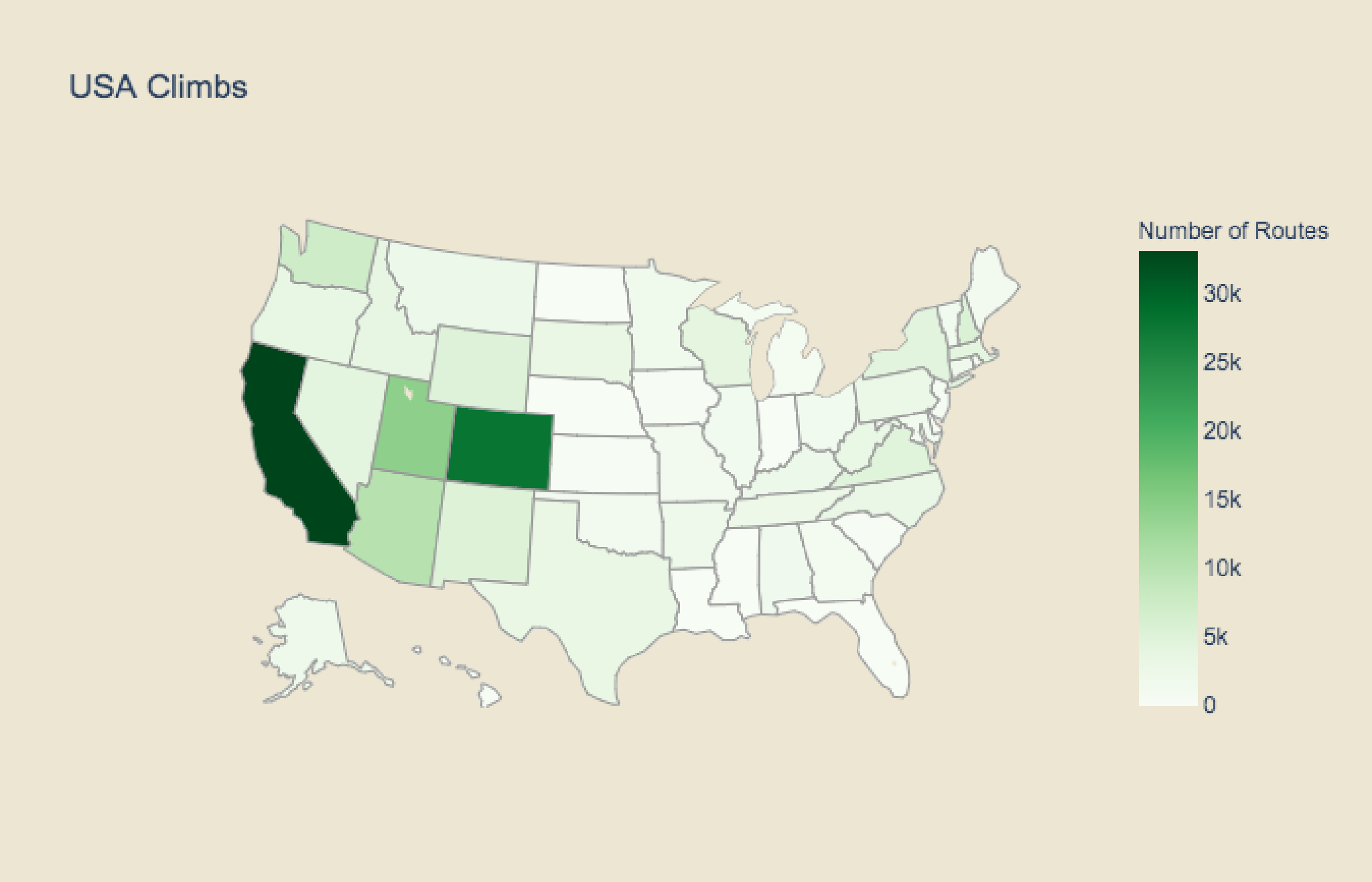
In the map below we can see where climbs are located in the United States. In particular we see that the top 5 states for number of climbing routes are California, Colorado, Utah, Arizona, and Washington. This is not surprising as we would expect for there to be more climbing in mountainous regions.
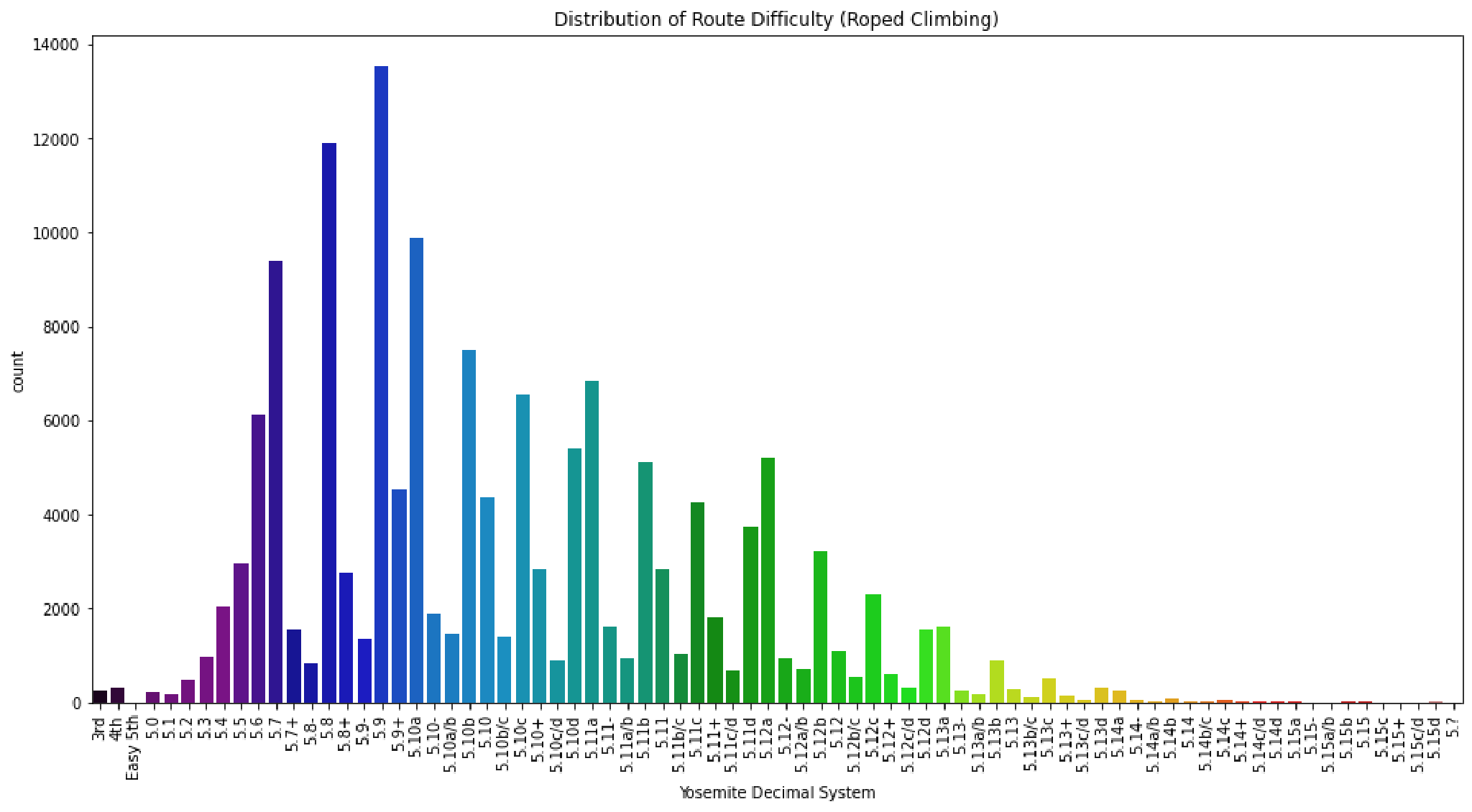
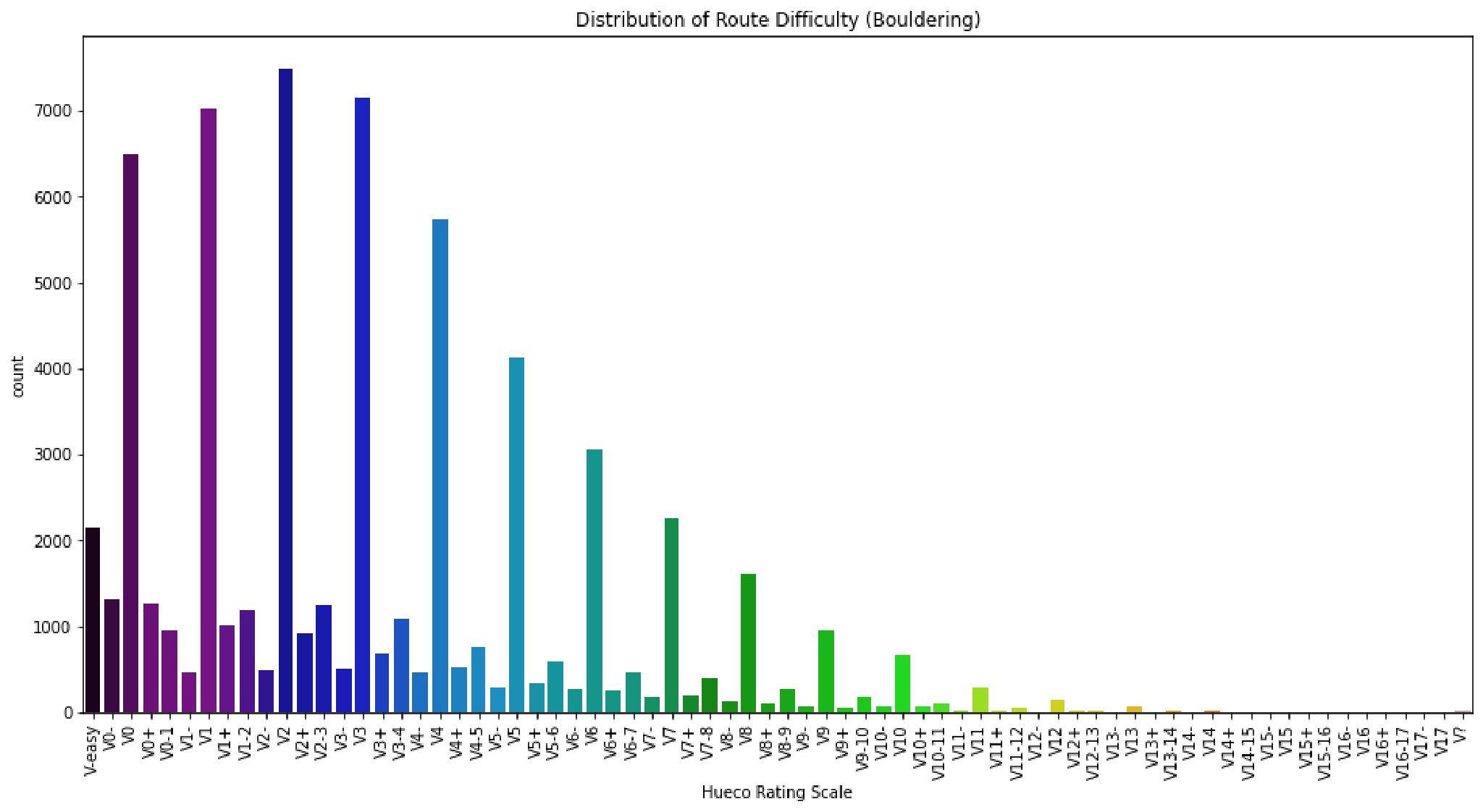
In the two plots below we see the distribution of route difficulty for both roped and boulder climbing routes respectively. With both types of climbing routes we find that there are less routes at the most difficult end of the spectrum. In addition most routes tend to be of a distinct grade and less split grades are used such as 5.10a/b or V2+.
Recommender System Models
K-Nearest Neighbors
K-Nearest Neighbors is a classic machine learning model which can be used for either regression or classification. The main adaptation of the algorithm to work for recommendations is the measure of similarity only considers item which both users have rated are considered. For this project a user based model was used thus similarity between users was used in order predict rating for unknown interactions.
Matrix Factorization
Matrix Factorization for recommender systems was popularized with the advent of the Netflix Competition. The basic idea behind the model is to reduce the large sparse matrix of user ratings into two smaller matrices which can be used to predict ratings for items a user has not interacted with. The values in these reduced matrices are initialized randomly and then learned using either stochastic gradient descent or alternating least squares in order to minimize the prediction error on the rating data available.
AutoRec
The AutoRec model is another rating estimation recommender system model based upon the idea of autoencoders [1]. Like the K-Nearest Neighbors method the model can be either user or item based. In this model either each row or column or the user-item rating matrix is used a input and the model attempts to recreate the input with shared weights in the model with unrated interactions masked from the calculation of the loss function. In this project a user based model was used in order to speed up computation for top-k recommendations.
Caser
Caser is a sequence-aware recommender model which takes into account sequences of items a user has interacted with to provide a personalized top-K ranked list [2]. Unlike the previous models Caser does not require explicit ratings for items. The model works by first using an embedding layer with dimension D for the sequence of the previous L items the user has interacted with to form an “image”. Then vertical and horizontal convolutional layers are applied and flatten, concatenated, and connected to a fully connected layer with D units. The output of the dense layer is concatenated with another embedding layer for the user id and finally connected to a fully connected output layer with I units where I is the set of all items.
Results
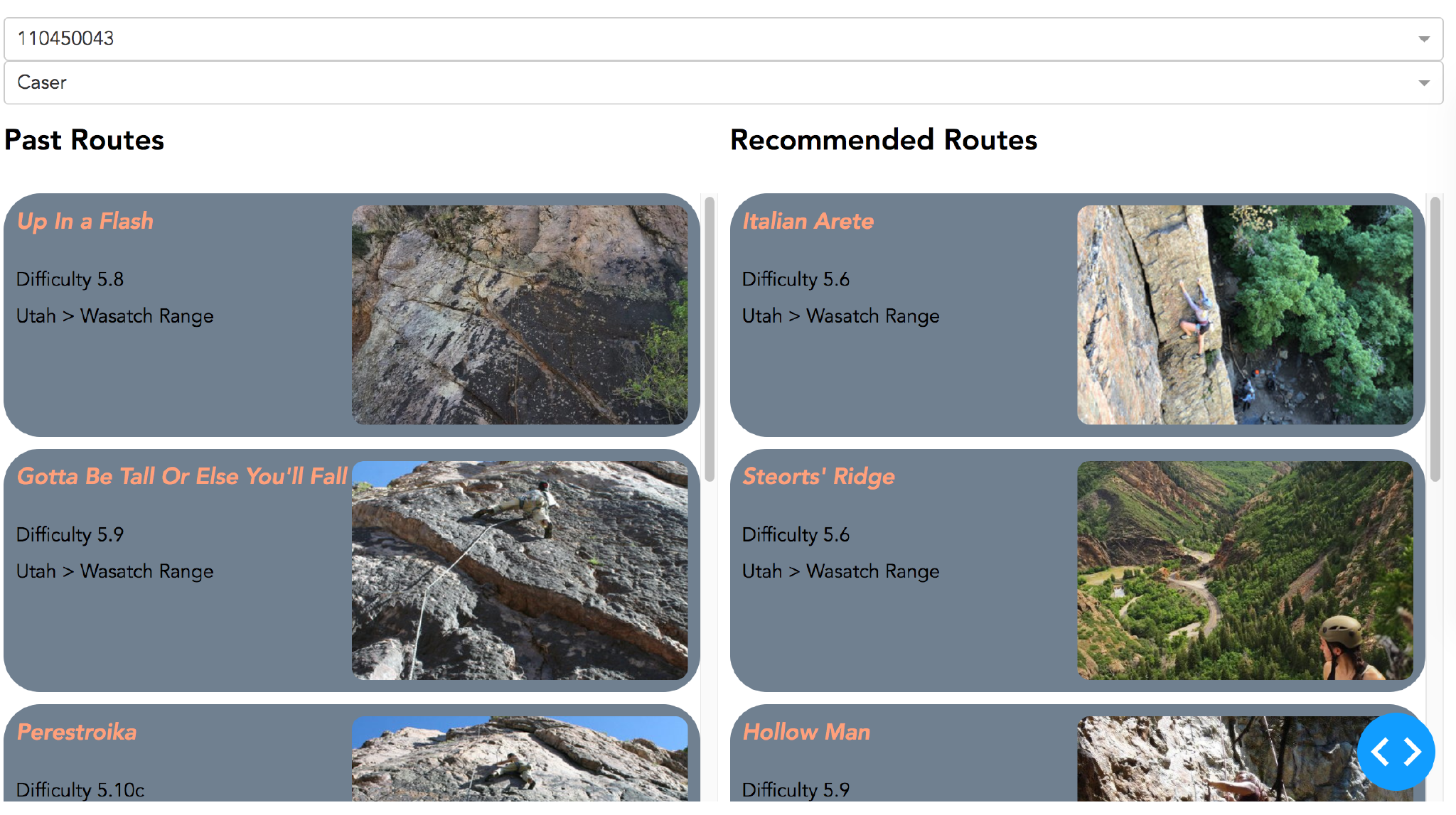
After building each model with optimized hyperparameters, the models were evaluated on the withheld test set comprising of 20% of the data. For the task of rating estimation the two metrics used were RMSE and MAE, while for the task of personalized top-k recommendations precision@k and recall@k were used with k = 1,5,10,25. From the results on the test set it was found that the Matrix Factorization model performed best at rating estimation while for personalized top-k recommendations the Caser model was the best. In addition we used a simple Dash application in order to visualize the personalized top-k recommendations of each model for a sample of users. From this we found that both the Matrix Factorization and AutoRec models tended to recommend a few popular routes for most users. For the Caser model we observed that the model would generally recommend routes that were similar in difficulty and location to routes that the user had most recently climbed.
References
[1] S. Sedhain, A. K. Menon, S. Sanner, and L. Xie, “AutoRec,” Proceedings of the 24th International Conference on World Wide Web - WWW 15 Companion, 2015.
[2] J. Tang and K. Wang, “Personalized Top-N Sequential Recommendation via Convolutional Sequence Embedding,” Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining - WSDM 18, 2018.